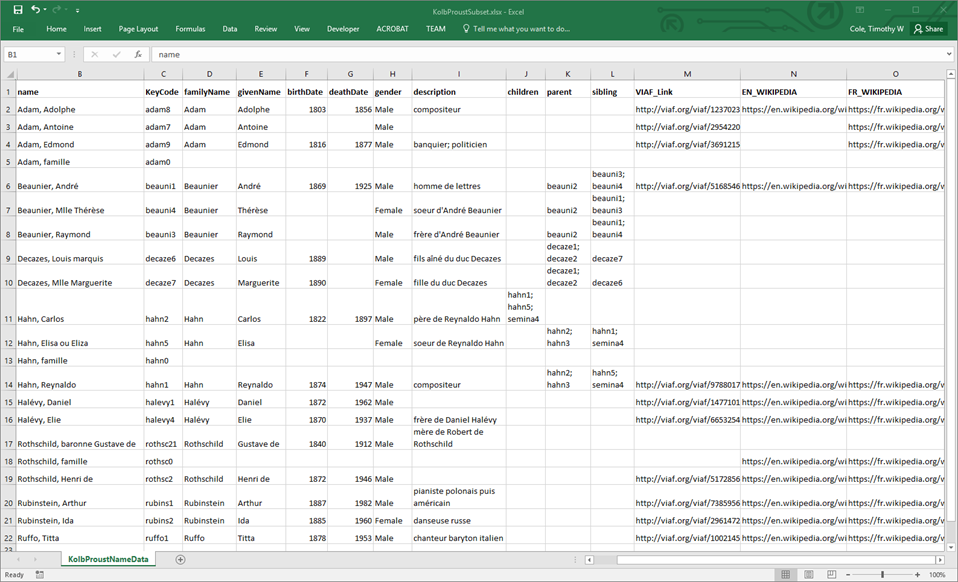
Figure 1: The Kolb-Proust Archive name authority Excel spreadsheet (simplified and abbreviated for this illustration)
The Transformative Potential of XSLT
Timothy W. Cole and Myung-Ja (MJ) K. Han
Introduction
When discussing EXstensible Stylesheet Language for Transformations (XSLT), a natural tendency is to focus on bridging XML Schemas, i.e., taking a set of XML documents that conform to one XML Schema Definition (XSD) and transforming these documents to conform to a different XSD. This is a common use case for XSLT; however, XSLT can be a useful tool for transforming XML-serialized information into non-XML formats as well. Transforming XML into HTML or into plain text illustrate incremental extensions of XML-to-XML use cases. The example described below illustrates a more ambitious use case -- showing how information about people and families contained in an Excel spreadsheet (saved as XML) can be re-serialized in JavaScript Object Notation for Linked Data (JSON-LD) using XSLT.
(This XSLT example was originally created as an illustration for Coding with XML for Efficiencies in Cataloging and Metadata: Practical Applications of XSD, XSLT, and XQuery (An ALCTS Monograph), published by ALA Editions, ISBN: 978-0-8389-1653-7. See: http://www.alastore.ala.org/detail.aspx?ID=12189.)
Background
This example is drawn from a real-world use case. The University of Illinois Kolb-Proust Archive for Research[1] includes a name authority database that has evolved over the 25 years of the project and now contains almost 7,000 names of people and families that were connected in various ways to the French author Marcel Proust and his family (based on the research of Philip Kolb). Until recently these name data have only been visible through the Archive's search interface (advanced search tab and as facets on search result views). Behind the scenes name strings and information about each person or family are stored in a relational database with a custom-to-the-project database schema. As part of a new project at Illinois focusing on Linked Open Data, all name descriptions from our database were exported for editing, augmentation and further processing to a Microsoft Excel Workbook (2016 version) containing a single spreadsheet. Figure 1 (next page) shows a simplified and abbreviated version of this spreadsheet.
The name metadata shown in Figure 1 have been organized into columns that align (by design) with the semantics of the Schema.org vocabulary. Schema.org is a collaborative ongoing project to develop, maintain and promote a data model for structured information on the Web.[2] The data model is designed to be inherently compatible with the W3C Resource Description Framework (RDF)[3] which underpins the Semantic Web and most current Linked Open Data services and applications. The task for which XSLT was needed focused on transforming the metadata contained in the spreadsheet to JSON-LD, an RDF-compatible serialization often used and well-understood by many Schema.org-based services (including harvesters). Essentially the goal of this transformation was to turn each row of the spreadsheet into an RDF graph (serialized as a JSON-LD text file) describing an entity of either schema.org/Person[4] or schema.org/Organization[5] (for this project families were treated as schema.org/Organizations).
JSON-LD
JSON[6] is a plain-text data-interchange format derived from the JavaScript programming language.[7] Code libraries now exist to make JSON easy to use with other popular programming languages. JSON is hierarchical and stores data in name-value pair structures. The names, always within quotation marks, are called keys. Each key is followed by a colon and then a value, which can be any of a string, a number, a Boolean true/false, an object (another set of name-value pairs), an array of any of the preceding, or null.
Figure 1: The Kolb-Proust Archive name authority Excel spreadsheet (simplified and abbreviated for this illustration)
JSON objects are delineated by curly braces ({ }). A JSON document instance in its entirety is a kind of JSON object, and so is itself enclosed in curly braces when serialized in a text file. Square brackets ([ ]) denote an array. Name-value pairs are separated one from another by commas. Figure 2 is a simple JSON document instance. As in XML, the indentation is not required but can be helpful for readability.
{
"title": "Using OAI-PMH",
"creator": [
"Timothy W. Cole",
"Muriel Foulonneau" ]
}
Figure 2: A simple illustration of a JSON document instance
RDF is designed to express sets of subject-predicate-object assertions, such as: the resource identified by http://www.worldcat.org/oclc/751406981 is of type (as defined in the RDF ontology) Book (as defined by http://schema.org/Book), has a title or name (as defined by http://schema.org/name), "Using OAI-PMH", and two creators (as defined by http://schema.org/creator) named "Timothy W. Cole" and "Muriel Foulonneau". These 6 assertions ('RDF triples') are graphically represented as shown in Figure 3. Note the insertion by the processing software (in this case the W3C RDF Validation Service[8]) of two intermediate nodes in the graph to represent the creators as objects, each of which is the subject of a name assertion.

Figure 3: Graphical representation of 6 assertions, aka RDF triples, about a book
JSON-LD adds special keys to facilitate serializing RDF graphs in JSON. One key, "@id", is used to express the identifier of a resource used as an RDF subject or object. Another key, "@type", is used to express the RDF type of a resource. Thus the graph of figure 3 can be serialized as shown in Figure 4.
{
"@id" : "http://www.worldcat.org/oclc/751406981",
"@type" : "http://schema.org/Book",
"http://schema.org/name": "Using OAI-PMH",
"http://schema.org/creator": [
{ "http://schema.org/name": "Timothy W. Cole" },
{ "http://schema.org/name": "Muriel Foulonneau"} ]
}
Figure 4:
JSON-LD adds one more special key, "@context", to further simplify how RDF graphs are expressed in JSON. This key is used as an easy way to declare namespaces used in an RDF graph and to provide a mapping of simple keys to namespaced properties (e.g, "name" mapped to "http://schema.org/name", and "creator" mapped to "http://schema.org/creator"). Figure 5 is a context document for this example, and Figure 6 is the JSON-LD document instance for this example, given this context document.
{
"@context": {
"type": "@type",
"id": "@id",
"schema": "http://schema.org/",
"rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"Book": {"@id": "schema:Book"},
"creator": { "@id": "schema:creator"},
"name": { "@id": "schema:name"}
}
}
Figure 5: The JSON-LD context document 'myContext.jsonld' provides mappings to simplify serialization
As can be seen (compare Figure 4 to Figure 6), reference to a context document can greatly enhance the readability of an RDF graph serialization in JSON-LD. Schema.org maintains its own context document which can be retrieved (using content negotiation) from http://schema.org.
{
"@context": "myContext.jsonld",
"id": "http://www.worldcat.org/oclc/751406981",
"type": "Book",
"name": "Using OAI-PMH",
"creator": [
{ "name": "Timothy W. Cole" },
{ "name": "Muriel Foulonneau" } ]
}
Figure 6: The serialization from Figure 4 simplified using the mappings of 'myContext.jsonld'.
So our goal in this exercise is to use XSLT to transform spreadsheet rows to JSON-LD document instances. For example, Row 1 of the spreadsheet shown in Figure 1 transforms to the JSON-LD shown in Figure 7.
{
"@context": "http://schema.org",
"id": "http://catalogdata.library.illinois.edu/lod/entities/Persons/kp/adam8",
"sameAs": ["http://viaf.org/viaf/12370239", "https://en.wikipedia.org/wiki/Adolphe_Adam",
"https://fr.wikipedia.org/wiki/Adolphe_Adam"],
"type": "Person",
"name": "Adam, Adolphe",
"familyName": "Adam",
"givenName": "Adolphe",
"birthDate": "1803",
"deathDate": "1856",
"gender": "Male",
"description": "compositeur"
}
Figure 7: Row 1 of the simplified Kolb-Proust Archive name-authority spreadsheet serialized as JSON-LD
The Source XML for the Transformation
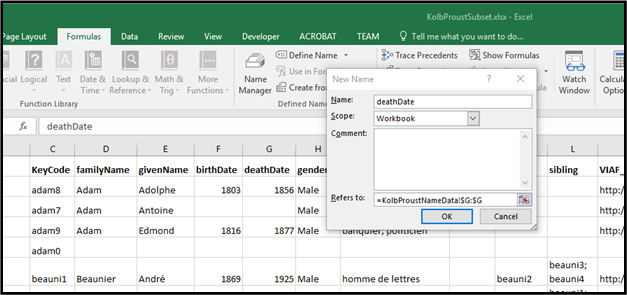
 As mentioned the metadata of interest
were edited in spreadsheet format. There are various options for exporting
these metadata to XML. One of the easiest is to save the spreadsheet ('Save As'
menu) in the Microsoft-defined "XML Spreadsheet 2003" format. Before
doing so it is useful to explicitly define a name for each column in the
spreadsheet. The name manager feature of Excel is used. This is normally done
to facilitate the use of column values in formulas, but also ensures that the
cells are all named in the XML serialization as well. Simply highlight the
column of interest and click on the 'Define Name' button visible under the
'Formulas' tab. By default the Define Name function will use the value in the
first row of the column as the default name. Click 'OK' and move on to the next
column until all are done (Figure 8).
As mentioned the metadata of interest
were edited in spreadsheet format. There are various options for exporting
these metadata to XML. One of the easiest is to save the spreadsheet ('Save As'
menu) in the Microsoft-defined "XML Spreadsheet 2003" format. Before
doing so it is useful to explicitly define a name for each column in the
spreadsheet. The name manager feature of Excel is used. This is normally done
to facilitate the use of column values in formulas, but also ensures that the
cells are all named in the XML serialization as well. Simply highlight the
column of interest and click on the 'Define Name' button visible under the
'Formulas' tab. By default the Define Name function will use the value in the
first row of the column as the default name. Click 'OK' and move on to the next
column until all are done (Figure 8).
Figure 8: Managing column names in Excel
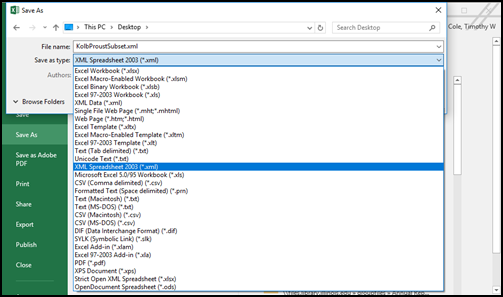
Figure 9: Saving an Excel spreadsheet in Microsoft's XML Spreadsheet 2003 format
Then use the File - Save As dialog (Figure 9) and select Save as type 'XML Spreadsheet 2003 (*.xml)'. The spreadsheet will be serialized as XML. Each row of the spreadsheet will be a node, as illustrated in Figure 10. Note that each Cell node in a Row node contains a Data node and a NamedCell node. The latter includes as an attribute the name of each Cell as established in the Define Name step described above.
<Row ss:AutoFitHeight="0" ss:Height="21.9375">
<Cell><Data ss:Type="Number">56</Data></Cell>
<Cell><Data ss:Type="String">Adam,
Adolphe</Data><NamedCell ss:Name="name"/></Cell>
<Cell><Data ss:Type="String">adam8</Data><NamedCell ss:Name="KeyCode"/></Cell>
<Cell><Data ss:Type="String">Adam</Data><NamedCell ss:Name="familyName"/></Cell>
<Cell><Data ss:Type="String">Adolphe</Data><NamedCell ss:Name="givenName"/></Cell>
<Cell><Data ss:Type="Number">1803</Data><NamedCell ss:Name="birthDate"/></Cell>
<Cell><Data ss:Type="Number">1856</Data><NamedCell ss:Name="deathDate"/></Cell>
<Cell><Data ss:Type="String">Male</Data><NamedCell ss:Name="gender"/></Cell>
<Cell><Data ss:Type="String">compositeur</Data><NamedCell ss:Name="description"/></Cell>
<Cell><Data ss:Type="String">http://viaf.org/viaf/12370239</Data><NamedCell
ss:Name="VIAF_Link"/></Cell>
<Cell><Data ss:Type="String">https://en.wikipedia.org/wiki/Adolphe_Adam</Data><NamedCell
ss:Name="EN_WIKIPEDIA"/></Cell>
<Cell><Data ss:Type="String">https://fr.wikipedia.org/wiki/Adolphe_Adam</Data><NamedCell
ss:Name="FR_WIKIPEDIA"/></Cell>
</Row>
figure 10: A row from the spreadsheet serialized in the XML Spreadsheet 2003 format
The XSLT Transform
1. Root element, namespace declaration and global variables: Figure 11 shows the stylesheet's root element opening tag (with attributes) as well as declarations for two globally scoped stylesheet variables, $needPrefix and $prefix having fixed values. These variables are used to ensure that local identifier values from the parent, sibling and children columns are transformed into global identifiers (URIs) before being added to the result-tree. Note that in addition to declaring the usual XSL/Transform and XMLSchema namespaces (namespace prefixes xsl: and xs:), an additional namespace prefix, ss:, is bound to a Microsoft spreadsheet-specific namespace. This allows for the selection in the stylesheet of essential elements and attributes found in the source XML file. Also note that this XSLT makes use of certain version 2.0 XPath and XSLT features, hence the version="2.0" attribute included on the root element.
<?xml version="1.0"
encoding="UTF-8"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"
version="2.0">
<!-- Global Variables: -->
<!-- these spreadsheet columns contain
local identifiers of related resources;
these values must be prefixed to
yield globally valid resource URIs -->
<xsl:variable name="needPrefix">
parent sibling children </xsl:variable>
<xsl:variable name="prefix">
http://catalogdata.library.illinois.edu/lod/entities/Persons/kp/</xsl:variable>
Figure 11: XSLT root element and global variable bindings
2. match="/" template and result document: Figure 12 shows the top portion of the stylesheet's main template, which matches on the root of the XML source-tree. Note that the first Row of the source XML simply recapitulates the column names and therefore can be skipped during the transform. This is accomplished by including the test for position()>1 in the initial for-each instruction's select attribute. The second test included in the select attribute ensures that all subsequent Rows having a NamedCell grandchild node with a Name attribute value of 'KeyCode' are transformed by the for-each instruction. The first step in transforming a Row is to bind 3 variables, $localID, $saveAs, $uri, to values found in the Row. These variables are used to set both the filename for saving the Row's JSON-LD serialization and the global identifier for the Person or Organization entity being described. A result-document instruction is used create the file for saving the result-tree. The value of the href attribute of this element becomes the name of the file to be saved. Since JSON-LD is a plain-text serialization, the output (method) is set to text. Then the initial curly brace, the JSON-LD context reference (same for all Rows) and the global identifier of the Person/Organization are written to the result-tree using xsl:text instructions.
<xsl:template match='/'>
<xsl:for-each
select="//ss:Row[position()>1][ss:Cell/ss:NamedCell/@ss:Name='KeyCode']">
<!-- this spreadsheet column contains
local identifier of the resource being
described by the row, from which the global resource URI and local file
location for saving can be derived
-->
<xsl:variable name="localId"
select="./ss:Cell[ss:NamedCell/@ss:Name='KeyCode']/ss:Data"/>
<xsl:variable name="saveAs" select="concat('NameGraphs/',$localId,
'.jsonld')"/>
<xsl:variable name='uri'
select="concat($prefix,
$localId )"/>
<xsl:result-document href="{$saveAs}" method='text'
exclude-result-prefixes="#all"
omit-xml-declaration="yes" indent="no" encoding="UTF-8">
<xsl:text>{
"@context": "http://schema.org"</xsl:text>
<xsl:text>,
"id": "</xsl:text><xsl:value-of select='$uri'/><xsl:text>"</xsl:text>
Figure 12: First part of the XSLT's main template (match='/')
3. The addValues named template: Figure 13 (next page) shows the next section of the main template. In this section of the transform, a variable, $myLinks, is bound. This variable will be a Row-specific node sequence containing 0, 1, or more than 1 "value" elements. A xsl:for-each instruction is used to populate $myLinks variable with strings drawn from the VIAF_Link, EN_WIKIPEDIA AND FR_WIKIPEDIA columns. These values are additional URLs for retrieving information about the person or family being described. In schema.org semantics these links are recorded as values of the sameAs predicate. Note that consistent with JSON-LD syntax, each URL is surrounded with quotes before being added to the $myLinks variable. Once the $myLinks variable has been populated, a named template, addValues (Figure 14), is called with 2 parameters, $valueKey and $valueArray. The string "sameAs" is provided for $valueKey, and the variable $myLinks is passed for the parameter $valueArray. The addValues template consists of a xsl:choose instruction that branches according to the length of the $valueArray node sequence. If consisting of only a single node, the contained string is written to the result-tree as the value of the sameAs key. If more than one node, an array of all the strings from the sequence is written to the result-tree as the value of the sameAs key. If zero nodes, nothing is written to the result-tree (absence of xsl:otherwise). Note the use of the separator attribute on the xsl:value-of instruction. If the xsl:value-of instruction's select attribute value is a node sequence, the value of the separator attribute will be used to delineate values of items in the sequence. Once control is passed back to the main match="/" template, another choose is used to write the type of object being described (Person or Organization) to the result-tree.
<!-- URIs found in these spreadsheet
columns will be conflated to yield the
value of the schema:sameAs property
for resource being described -->
<xsl:variable name="myLinks">
<xsl:for-each select="./ss:Cell[ss:NamedCell/@ss:Name='VIAF_Link'
or
ss:NamedCell/@ss:Name='EN_WIKIPEDIA'
or
ss:NamedCell/@ss:Name='FR_WIKIPEDIA']/ss:Data">
<value>"<xsl:value-of select="."/>"</value>
</xsl:for-each>
</xsl:variable>
<xsl:call-template name="addValues">
<xsl:with-param name="valueKey">sameAs</xsl:with-param>
<xsl:with-param name="valueArray" select="$myLinks" />
</xsl:call-template>
<xsl:choose>
<xsl:when
test="contains(./ss:Cell[ss:NamedCell/@ss:Name='name']/ss:Data,
'famille')">
<xsl:text>,
"type": "Organization"</xsl:text>
</xsl:when>
<xsl:otherwise>
<xsl:text>,
"type": "Person"</xsl:text>
</xsl:otherwise>
</xsl:choose>
Figure 13: Binding the $myLinks variable, calling the addValues template, and expressing the object type
<xsl:template name="addValues">
<xsl:param name="valueArray" required="yes"/>
<xsl:param name="valueKey" required="yes" />
<xsl:choose>
<xsl:when test="count($valueArray/value)=1">
<xsl:text>,
"</xsl:text>
<xsl:value-of select="$valueKey"/>
<xsl:text>": </xsl:text>
<xsl:value-of select="$valueArray/value"/>
</xsl:when>
<xsl:when test="count($valueArray/value)>1">
<xsl:text>,
"</xsl:text>
<xsl:value-of select="$valueKey"/>
<xsl:text>": [</xsl:text>
<xsl:value-of select="$valueArray/value" separator=", "/>
<xsl:text>]</xsl:text>
</xsl:when>
</xsl:choose>
</xsl:template>
Figure 14: The addValues named template
4. The parseValues named template: The rest of the match="/" template is shown in Figure 15. This final section of the template populates the remaining properties of the JSON-LD serialized RDF description and then adds the closing curly brace. The challenge in transforming spreadsheet column values in this section of the template is the reverse of the previous. Each column maps to a single key in the JSON-LD serialization; however, some of the per-column strings (e.g., in the sibling column) may in certain rows contain multiple conflated values delineated by a semi-colon-space character sequence. In these instances it is necessary to transform these conflated strings into a JSON-LD array. Also, as mentioned above, values in columns containing local identifiers must be prefixed before being saved to the result-tree in order to transform locally unique identifiers into globally unique identifiers. To avoid redundancy in the match="/" template, these tasks are done in a named template, parseValues, shown in Figure 16.
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">name</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">familyName</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">givenName</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">birthDate</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">deathDate</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">gender</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">description</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">parent</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">sibling</xsl:with-param></xsl:call-template>
<xsl:call-template name="parseValues">
<xsl:with-param name="valueKey">children</xsl:with-param></xsl:call-template>
<xsl:text> }</xsl:text>
</xsl:result-document>
</xsl:for-each>
</xsl:template>
Figure 15: The rest of the XSLT's main template
The parseValues template requires a single parameter, $valueKey. This parameter is used to pass in the column name which is also the JSON-LD key that will be written to the result-tree (i.e., and also the Schema.org predicate corresponding to the column). The task of the parseValues template is to construct a node sequence, which is bound to the $valueArray variable, containing the string value(s) found in the column identified by the $valueKey. A xsl:for-each instruction is used to select the column value. Note that the select attribute value for this for-each instruction is determined using the XPath 2.0 tokenize function to split the spreadsheet value on semi-colon-space sequence when found. Note also that columns having a name in the $needPrefix list are added to the node sequence with a prefix (so as to create globally unique identifiers from the locally unique identifier values contained in the spreadsheet column). Once the $valueArray variable has been populated, the parseValues template then calls the addValues template and output is written to the result-tree by that template as described above.
<xsl:template name="parseValues">
<xsl:param name="valueKey" required="yes"/>
<xsl:variable name="valueArray">
<xsl:for-each
select="tokenize(./ss:Cell[ss:NamedCell/@ss:Name=$valueKey]/ss:Data,
'; ')">
<xsl:choose>
<xsl:when
test="contains($needPrefix,
$valueKey)">
<value>"<xsl:value-of select="$prefix"/><xsl:value-of select="."/>"</value>
</xsl:when>
<xsl:otherwise>
<value>"<xsl:value-of select="."/>"</value>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</xsl:variable>
<xsl:call-template name="addValues">
<xsl:with-param name="valueKey" select="$valueKey"/>
<xsl:with-param name="valueArray" select="$valueArray"/>
</xsl:call-template>
</xsl:template>
Figure 16: parseValues named template
Summary
This XSLT example illustrates how XSLT can be integrated into real-world workflows and facilitate the bridging of even non-XML serializations of information. Obviously the plain-text nature of JSON-LD and the similarities between JSON and XML, facilitates the use of XSLT for this workflow, as does being able to save spreadsheets in an XML serialization. But the attraction of using XSLT is the power of named templates, the availability of the xsl:result-document instruction and the utility of features like the separator attribute for the xsl:value-of element and the tokenize XPath function. The ability to create both globally-scoped and template-scope variables is useful, especially given the option to bind node-sequences to these variables. This example illustrates the potential of XSLT as a programming language.
[3] The top-level specification for version 1.1 of RDF is: http://www.w3.org/TR/rdf11-concepts/
[6] http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-404.pdf, http://www.json.org/, https://tools.ietf.org/pdf/rfc7159.pdf